 Banking
Banking
 Healthcare
Healthcare
 Energy
Energy
 Manufacturing
Manufacturing
 Education
Education
 Highlights
Highlights
 Blogs
Blogs
 Whitepapers
Whitepapers

How to translate data access into measurable business outcomes
In 1999, NASA lost the Mars Climate Orbiter nine months into its journey.
One engineering team had calculated thruster forces in metric units while another operated in imperial. A governance mechanism did not exist to surface the discrepancy before it caused the damage. While the telemetry data was accurate and navigation software performed as designed, a $327 million mission was lost because two teams working from the same data did not share a common framework for interpreting its meaning.
The failure was architectural, and not technical, which matters even more today. Most enterprises are replicating the same error at a greater scale, misattributing poor returns to data quality, and investing further in a layer that is not the problem.
Why Enterprise AI Initiatives Fail at Data Democratization
Data democratization is the organizational practice of making data accessible to all employees, so they can use it to make informed decisions. In enterprise AI context, this definition is not sufficient for employees to reach the data. They must be able to interpret it without reconstructing the organizational knowledge that experienced colleagues developed over years. While most programs have addressed the first requirement, they have not addressed the second.
Organizations have invested significantly in data accessibility over the past decade, deploying self-service analytics platforms, building data catalogs, establishing governance frameworks, and provisioning access across functions. While the existing infrastructure is highly capable, generating justifiable financial returns on these capital investments remains a challenge.
MIT CISR’s research, spanning thousands of organizations, found that 72% of employees in organizations that have already provisioned data access do not draw on available assets. A concurrent survey of 850 executives by Huwise and Odoxa quantified the execution gap with greater precision: 64% of employees report satisfaction with their data access, while only 26% say data materially benefits their day-to-day decision-making. The disparity between access satisfaction and realized value reveals a fundamental flaw in the design of data systems.
The usual response has been to invest further in the same layer, through better governance, cleaner pipelines, and broader coverage, on the assumption that the problem lies in the data quality. Gartner research has identified data literacy, rather than data access, as the primary barrier to becoming data-driven.
Yet the organizational response of structured training programs and documentation initiatives has consistently underperformed, because it does not address the underlying cause. The cause is the lack of an interpretive layer, which is the organizational knowledge of the contextual meaning, historical usage, and known constraints of every dataset.
What is the Interpretive Layer
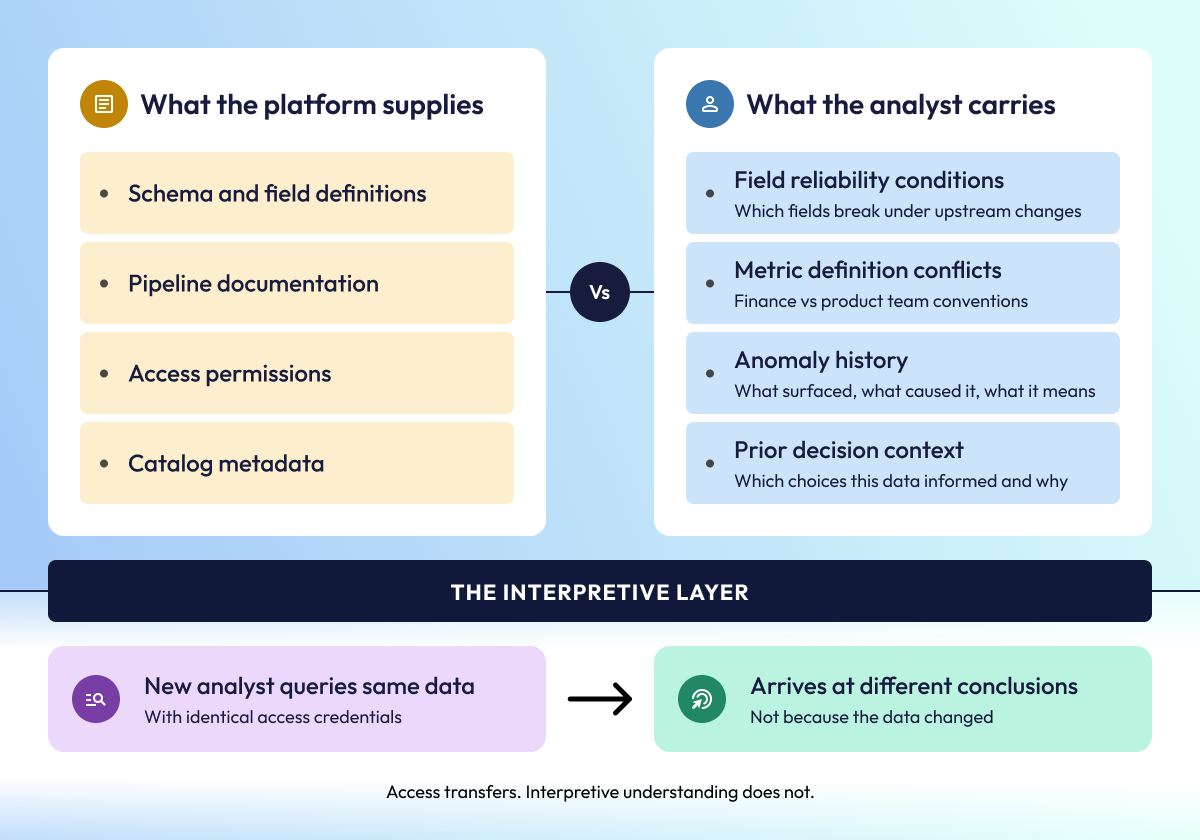
The experienced practitioners apply a form of contextual understanding every time they engage with data, yet it rarely transfers beyond the individuals who developed it. MIT CISR’s research states that provisioning access does not automatically produce use, because access credentials and interpretive understanding are not the same organizational resource. While one can be distributed through a platform, the other must be deliberately built and preserved as an institutional asset.
An experienced analyst brings two distinct things to a query:
- the data itself, which the platform supplies, and
- everything they know about the data that the platform does not contain.
This second layer encompasses the semantic context, usage history, and reliability boundaries that determine how data can be used. It is distinct from data access and is not automatically captured by analytics platforms. This undocumented organizational knowledge is built through sustained engagement with specific datasets, and it resides with the individuals who developed it.
As a result, colleagues with identical platform access but without the interpretive foundation query the same dataset and arrive at different conclusions. At enterprise scale, with large data estates and rotating analytical populations, this gap widens against the return on every data infrastructure investment the organization has made.
The software engineering disciplines have long recognized this failure mode under the concept of the bus factor: the number of team members whose departure would render a system unmaintainable. Applied to enterprise data programs, most organizations operate with a domain-level data bus factor of one or two. A single analyst departure leaves an interpretive vacuum.
For most organizations, this gap existed for years. The acceleration of enterprise AI investment has amplified it. Every AI initiative deployed on top of an underprepared data estate inherits the same architectural failure at greater speed and scale, and with far less visibility into the gaps.
From Data Access to Data Intelligence
The organizations generating the strongest returns from their data investments possess a superior ability to integrate AI and data into everyday operations. MIT CISR found that in organizations where at least a third of employees actively draw on data assets, data monetization contributes 15% of total revenues, compared to under 5% in organizations with lower utilization.
The performance differential is attributable to whether employees engaging with data have sufficient interpretive context to derive actionable meaning from it. This is the difference between Data Access and Data Intelligence.
Data Access is the provisioning of retrieval rights. An organization that has deployed a self-service analytics platform, opened its data catalog, and established role-based access controls has achieved Data Access at enterprise scale. The employees can access the data they are authorized to see.
Data Intelligence is retrieval rights combined with the organizational infrastructure that makes retrieval meaningful. It encompasses authoritative documentation of what each dataset represents, how it was produced, what its known limitations are under specific analytical conditions, and how it has been interpreted in prior analytical work.
Data intelligence transforms raw data into a reliable foundation. It shifts search queries from producing confident but inaccurate results to correct conclusions by grounding outputs in context, validation, and domain-specific meaning.
Bridging the gap between the two requires treating the interpretive layer as a primary infrastructure deliverable. When an analyst develops a nuanced understanding of a specific dataset, it should become a durable organizational asset.
10x Data User: Data Intelligence in Your Organization
The operational evidence that Data Intelligence is achievable exists within every enterprise, visible in the performance of a specific category of practitioners present in every function.
The pattern is consistent across functions:
- In sales, it is the analyst who knows which pipeline metrics predict deal closure before the forecast makes it visible.
- In operations, it is the practitioner who detects an anomaly in supply chain data before it escalates into a stock event.
- In finance, it is the professional who recognizes that two business units are calculating the same metric differently and reconciles the discrepancy before it reaches the board.
These practitioners extract disproportionate value from the same data assets their colleagues underutilize, and their advantage is the accumulated interpretive capital, organizational intelligence about specific datasets built through sustained engagement, and institutional memory that develops over time.
The objective of a mature data democratization program is to capture that interpretive capital and make it a usable organizational asset, accessible to every analyst who queries the relevant datasets, independent of whether the practitioner who developed it.
Engineering Interpretive Context as Organizational Infrastructure
In most organizations, the output of analytical work is the end result in the form of the report, dashboard, or model output. The interpretive reasoning that produces it, including the judgment applied to assess data quality conditions, the business rule that determined inclusion criteria, and the prior decision that established the metric convention in use, is treated as process rather than product. It remains uncaptured, so the next analyst who queries the same data needs to reconstruct it independently.
Treating the interpretive layer as infrastructure changes this model in measurable ways:
- When an analyst documents a known data quality constraint, that record becomes part of the dataset’s interpretive history, accessible to every subsequent user.
- When a business unit interprets a metric in a specific direction to support a strategic decision, that convention becomes accessible to any analyst who later queries the same metric.
- When an analytical model is constructed on top of a dataset, the assumptions embedded in its design are recoverable by the team that inherits it, regardless of organizational continuity.
The operational benefits of doing this are concrete and measurable:
- Analyst onboarding cycles shorten as accumulated interpretive history becomes accessible rather than requiring reconstruction from first principles.
- Analytical errors cease to repeat across business units, working from shared source tables, as the conditions that produce them are documented at the dataset level.
- Cross-functional decision consistency improves as shared interpretive conventions replace the independently derived ones that currently generate conflicting conclusions from identical underlying data.
Evaluate Where Your Program Stands
For data and analytics leaders assessing the maturity of their data democratization initiative, the relevant measure has changed. Provisioning access to a growing proportion of employees is not the indicator of progress it once appeared to be. The more precise measure is whether the interpretive context that enables accurate, consistent data use is being systematically captured and maintained.
The indicators of an access-oriented program across organizations include:
- Analysts reconstruct domain context independently on each new engagement, without an accessible record of prior interpretive decisions or established conventions.
- Data quality constraints are identified in parallel by separate teams working from shared source tables, without an organizational mechanism to capture or distribute prior findings.
- Metric definitions diverge across business units as functions develop independent analytical conventions.
The indicators of a program that has built interpretive infrastructure are:
- Interpretive context is captured as a standard output of analytical work and follows the data as an organizational asset, independent of individual personnel continuity.
- Known data quality constraints are surfaced at the point of access, enabling analysts to account for them before conclusions are reached.
- Cross-functional decision consistency improves as documented interpretive conventions replace independently derived ones across business units working from shared data sources.
Most organizations conducting this assessment will find themselves in the first set of indicators. It is the predictable result of programs built against an incomplete definition of data democratization requirements.
Bernard Marr defined data democratization’s goal as to ensure anyone can use data without barriers to access or understanding. Understanding was always part of the definition but most programs remain focused on access.
Most enterprise AI initiatives being planned today will operate on data estates where this knowledge still resides in individuals rather than in systems. Organizations that address this will find that every prior data investment begins to return more than it did before.
The next article in the AI readiness series will go deeper into the interpretive layer, and how to make it a part of data democratization in your organization.